(1. 新疆大学信息科学与工程学院,乌鲁木齐 830046)
摘要:模式识别课程主要包括特征提取和分类器两大内容。本论文案例中,特征提取部分使用K-L变换,分类器部分使用支持向量机 (SVM)。通过教学案例,对模式识别整个过程有更深刻的理解,能够根据自己的设计对K-L算法和SVM算法有一个深刻地认识,从而培养学生创新性思维和动手能力。
关键词:模式识别、人脸识别、K-L变换、支持向量机
基金项目:自治区研究生教育教学改革项目(NO.XJ2022GY09);新疆大学2021校级研究生教育教学改革项目(NO.XJDX2021YJG10)
"Pattern Recognition" Teaching Case-Face Recognition Based on K-L Transform
Mayire Ibrayim1, Kurban Ubul1
(1. School of Information Science and Engineering, Xinjiang University, Urumqi 830046)
Abstract:The pattern recognition course mainly includes two major contents: feature extraction and classifier. In the case of this paper, the feature extraction part uses K-L transformation, and the classifier part uses support vector machine (SVM). Through teaching cases, students can have a deeper understanding of the whole process of pattern recognition, and can have a deep understanding of K-L algorithm and SVM algorithm according to their own design, so as to cultivate students' innovative thinking and practical ability.
Keywords:Pattern recognition, face recognition, K-L transform, support vector machine sorting
1前言
模式识别课程教学目的是,通过本课程的学习,使学生掌握模式识别的基本概念、基本原理、基本分析方法和算法[1]。并培养学生能够利用模式识别的理论方法,并运用其技能解决本专业和相关领域的实际问题的能力,了解模式识别的发展方向和应用情况。学生能提高使用计算机进行模式识别分析和计算的能力。模式识别课程不仅对相似性度量方法、特征提取和选择方法、各种模式识别方法特点进行分析能力的培养,而且也要注意培养针对具体应用选择合适的模式识别方法能力的培养[2-5]
面部识别是将被测面部的信息内容与数据库查询中的信息内容进行匹配的整个过程[6]。所测量的面部信息内容可以是照片,监视摄像机即时捕获的界面或存储的视频信息内容。详细的面部识别过程包括四个完整过程:面部识别算法,图像预处理,svm算法和面部匹配[7]。人脸识别算法是人脸识别的第一步,主要是检查图像中并明确定义照片中的人脸部分,以便以后使用。图像预处理也是面部识别的重要部分,主要是解决检测到的面部区域。接下来最重要的一个步骤就是图像特征提取,不仅要考虑人脸类内差距和类间差距,还需要考虑光照、姿态等影响因素的影响,本文选用近几年研究火热的卷积神经网络进行特征提取,相比传统的特征提取方法, 可以获得更具有区分性的人脸特征。最后进行特征对比,把上一步骤提取到的人脸特征和数据库中的人脸信息通过欧氏距离或者联合贝叶斯法进行相似度比较,最终完成人脸识别。
本文使用比较直观的“基于K-L特征变换的SVM人脸识别”作为例子讲解一个包括特征提取和分类器的整个模式识别过程。K-L变换和SVM是效果比较好的模式识别中特征提取和分类典型方法,容易实现、易于理解。
2K-L特征变换
K-L变换是一种基于图像统计特性的变换,它的协方差矩阵除了对角线以外的元素都是0,消除了数据之间的相关性,从而在信息压缩方面具有重要的作用。
在模式识别和图像处理中一个重要的问题就是数据降维,在实际的模式识别问题中,我们选择的特征经常彼此相关,在识别这些特征时,数量很多,大部分都是无用的。如果我们能减少特征的数量,即减少特征空间的维数,那么我们将可以使用更小的存储和计算度获得更好的准确性。
K-L变换的目的是寻找任意统计分布的数据集合主要分量的子集。基向量互相正交,使原始数据集合变换到主向量空间,使单一数据样本的互相关性降到最低。
我们设原始数据为x,变换后的特征为y,变换矩阵为A。则
![]() (1)
(1)
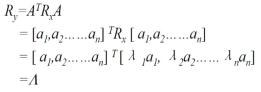 (2)
(2)
Λ为对角矩阵,对角线上的元素只有特征值,达到变换后不相关的目的。
我们选择其中较大的特征值,舍去其中较小的特征值,即可以达到降维,损失的能量也就越小。
K-L变换的提取步骤为:
(1)平移坐标系,将模式总体的均值向量作为新向量坐标系的起点。
(2)求出自相关矩阵Rx
(3)求出Rx的特征值和对应的特征向量
(4)将特征值从大到小排序,取前m个大的特征值构成的特征向量构成变换矩阵。
(5)将n维向量变为新的m维向量
3支持向量机(SVM)
SVM线性分类器解决的问题是,根据一个带有类别标号的训练集合,通过学习一个线性分类面,使得训练集合按照类别进行划分。线性分类面函数形式为:
![]() (3)
(3)
wT,b是分类面函数参数,x是输入的样本, wT权向量,b是偏移量。
学习过程是,从给定的训练样本确定wT和b这两个参数。得到参数以后,就确定了分类面,从而可以对输入样本进行分类。
![]() (4)
(4)
如果w相同,则分类面是平行的,b是一个偏移量。
最小化目标函数和约束条件如下:
 (5)
(5)
关键问题就是最优求解,构造Lagrange函数
![]() (6)
(6)
KKT条件
 (7)
(7)
4实现代码
我们将在Wild数据集中使用带标签的人脸,该数据集中包含了数千张各种公众人物的照片。Scikit-Learn内置了数据集的特征提取器,使用K-L算法对图片的特征维度进行降维处理,最后通过SVM分类器进行分类。
4.1 数据读取
读取人脸数据,选取同样类别的样本数量大于60张的人物作为分类类别。相关代码如下:
from sklearn.datasets import fetch_lfw_people
faces = fetch_lfw_people(min_faces_per_person=60)
print(faces.target_names)
print(faces.images.shape)
#print(faces)
4.2 数据降维
由于一张图片的像素点为62×47,所以一张图片有2914个特征,同时,K-L变换的变换矩阵可以有很多种(二阶矩阵、协方差矩阵、总类内离散度矩阵等等)。当K-L变换矩阵为协方差矩阵时,等同于PCA,因此本次实验选用PCA进行降维操作,将2914维的特征降到150维。相关代码如下:
from sklearn.svm import SVC
#from sklearn.decomposition import RandomizedPCA
from sklearn.decomposition import PCA
from sklearn.pipeline import make_pipeline
#数据降维到150维
import numpy as np
from sklearn.preprocessing import StandardScaler #数据归一标准化
def PCA(n):
X_std = StandardScaler().fit_transform(n)
mean_vec = np.mean(X_std, axis=0)#求每列的均值
cov_mat = (X_std - mean_vec).T.dot((X_std - mean_vec)) / (X_std.shape[0]-1)#求解协方差矩阵
eig_vals, eig_vecs = np.linalg.eig(cov_mat)#求解特征值和特征向量
ind = np.argsort(-1*eig_vals)
matrix_w = [eig_vecs[:,ind[i]] for i in range(150)]
matrix_w = np.transpose(matrix_w)
Y = X_std.dot(matrix_w)
return Y.real
Y=PCA(Xtrain)
model1 = SVC(C=10,kernel='rbf',gamma=0.0001, class_weight='balanced')
model1.fit(Y, ytrain)
Y1=PCA(Xtest)
yfit = model1.predict(Y1)
4.3 结果展示
通过SVM分类得到的预测数据与真实数据进行比对并绘图展示,计算精确度、敏感度、f1-score得分,并绘制混淆矩阵。相关代码如下:
fig, ax = plt.subplots(4, 6,figsize=(16, 6))
for i, axi in enumerate(ax.flat):
axi.imshow(Xtest[i].reshape(62, 47), cmap='bone')
axi.set(xticks=[], yticks=[])
axi.set_xlabel(faces.target_names[yfit[i]],
color='black' if yfit[i] == ytest[i] else 'red')
fig.suptitle('Predicted Names; Incorrect Labels in Red', size=14);
当将特征维度降为150维,最终得到正确率,计算得分相关代码如下:
from sklearn.metrics import classification_report#实用
print(classification_report(ytest, yfit, target_names=faces.target_names))
![D2]~VV)](HFMI@VZUG8F]$Y](/convert/2022-08-23/file_166123396297101985.008.png)
图1 当预测正确图片下的名字为黑色,错误为红色
5结语
以实验操作为主的教学是高等教育不可缺少的重要组成部分, 是巩固理论知识的有效途径,是培养具有创新精神和实践能力的高素质工程技术人才的重要环节。模式识别是实践性很强的一门课程,本文我们用具体实例来详细介绍了人脸识别的方法和步骤。在学习完成模式识别理论课的基础上,通过模式识别案例引导学生重温模式识别各分支和方法的基本概念和原理,并在计算机上进行验证实验,实际操作和观察图像模式识别的过程、运行结果,提倡学生对现有程序的修改和完善。
参考文献:
[1] 彭德巍.人工智能课程实验案例研究与实践[J].大学教育.2021(2).71-74.
[2] 张竞成,袁琳,陈丰农,等.结合科研的“模式识别”研究生教学改革探索与实践[J].科技视界.2019,(6).200-201.
[3]张立国,张培恒,金梅,等."模式识别"课程案例式教学的探索与实践[J].教育现代化,2018,5(8):159-160
[4] 王兵,王培珍.模式识别课程教学的探索与实践[J].安徽工业大学学报:社会科学版,2013,30(3):102-103.
[5] 张立国,王博.基于案例式的"模式识别"课程教学改革研究[J].教育现代化,2018,5(3):62-64
[6] 苏楠,吴冰,徐伟,等.人脸识别综合技术的发展[J].信息安全研究.2016(1):33-39.
[7] 夏志强.人脸识别综述[J].电子世界.2017(23):74-76.
作者简介:
玛依热·依布拉音(1981—),女,博士,副教授,硕士生导师,研究方向为智能图像处理
库尔班·吾布力(1974—),男,博士,教授,博士生导师,研究方向为模式识别
第 1 页 共 6 页

客服QQ:30444492琼网文【2021】1550-113号
增值电信业务经营许可证:琼B2-20210322
出版物经营许可证:新出发龙华出字第(2021)009号
广播电视节目制作经营许可证:(琼)字第00779号
版权所有 ©2002-2024 期刊网(www.qikanchina.com) 琼ICP备2021005105号



