(中核核电运行管理有限公司,浙江 嘉兴 314300)
摘要:核电厂时序数据的深化应用从侧面反映了电厂数字化的程度。随着大数据技术的逐渐成熟,新的应用场景不断推进,对多电厂核心工业控制系统(DCS)时序数据外传应用提供了很好的解决方案。本文结合秦山核电应用实践,通过梳理各机组DCS系统的类型、厂家、型号,以及其支持的数据传输协议,在确保网络安全规范的前提下,优化数据传输架构,定制开发DCS-PI数据传输接口。同时,利用Hadoop大数据平台的高性能存储、缓存和并发机制,设计新的实时数据集成应用架构。颠覆原有PI系统单节点结构设计模式,利用大数据平台提升实时数据的传输、存储和数据利用的效率、可靠性的问题。
关键词:PI数据库 Hadoop 实时数据传输
Research on real-time data transmission and application architecture optimization of nuclear power plant
CHEN yu
(CNNC Nuclear Power Operation Management Co.Ltd.,Jiaxing of Zhejiang Prov.314300,China;
Abstract: Application of nuclear power plant time series data has reflected the popularity of power plant digitizing. Along with the ample studied data technology has been collected progressively and moving forward, the new application scenario has also deepening. Provide the solutions of series data transmission at multi-power plant DCS system. In this thesis, based on QinShan power plant actual real time scenario, through sorting out respective DCS system type, manufacturer, model and supported data transmission protocol, optimize data transfer architecture while ensuring network security specifications, customize development on DCS to PI data transmission transceiver port. Meanwhile by utilizing Hadoop data platform high performance storage, buffering & concurrency mechanism, design the new real time data structure. By sub versing the origin PI system’s structure. Improve the performance and reliability of real time data transmission、storage and data utilization by using big data platform.
Keywords: PI system, Hadoop, real time data transmission
一、现存问题分析
随着核电大数据与数字核电应用场景的逐步增加和深入,大数据相关的研究项目也逐年落地。秦山核电现有四个生产单元,包括秦一厂一台机组、秦二厂四台机组、秦三厂两台机组和方家山两台共计九台机组。由于四个生产单元采用了不同设计,每个机组的核心工业控制系统均有差别。并且由于建设设计标准不一致,部分DCS在设计初期没有具备数据外传的条件。
传统的时序数据库以其去事务性、高压缩比、高读写性、全生命周期的数据保存等优势,在过去很长一点时间都非常受用户喜欢,但在大数据计算和性能分析需求爆增的情况下, 接入时序数据库的应用系统越来越多,采用传统的单机架构的时序数据库产品受到单台计算机处理能力的限制,已经无法满足这种持续增长的时序数据处理工作。如果无法实现对历史数据高效处理,数据价值的体现将大打折扣,对于企业的精细化发展不利。
二、研究思路
通过梳理各机组DCS系统的类型、厂家、型号,以及其支持的数据传输协议,按照可行性,稳定性,可配置性等因素选择最优协议,定制化开发DCS数据传输接口。最终,秦一厂和秦二厂1,2号机组采用OPC通用接口,秦二厂3,4号采用UDP接口协议。其中,UDP协议为定制化协议,其利用DCS和总线系统指定的端口进行实时数据的接收,采用被动监听端口和接收数据的方式进行数据采集,由于采用此协议不会向DCS和总线系统发送任何数据,从而避免由于人为或者病毒可能对DCS产生影响,确保了网络安全的要求。
搭建新的时序数据库的数据传输和存储架构是技术优化关键。根据核电厂网络安全管理规范要求,其他生产单元的数据传输链路(即秦三厂不可以使用秦二厂的数据链路)不能复用,且网络上生产大区需要与管理大区物理隔离。为满足安全管理要求,需要将已有数据架构推广至其他生产单元,完成全公司生产时序数据架构的搭建。
时序数据传输和存储工作的完成,标志秦山核电所有机组的生产时序数据传输链路的落地。但随着电厂实时数据的涵盖面的扩大,以及可预期的持续增长性。传统的时序数据库产品受到计算机处理能力的限制。比如ERDB系统在进行长周期性能计算的时候,PI系统的反馈时间上升至数十秒,影响了数据采集的稳定性。为了应对海量数据处理的需求,将数据库架构调整为大数据库平台架构,可以突破单机处理能力的限制,采用分布式计算的技术,极大地拓宽时序数据库产品的处理能力。
三、建设方法与验证
3.1通过DCS定制化数据传输接口的开发,完成对电厂9台机组PI系统的推广部署
本章节主要描述方家山、秦一厂、秦三厂等生产单元的数据架构的建设及优化。由于秦三厂在电厂设计中充分考虑了数据外传,系统架构上比较合理,且安全性也符合标准。所以在新链路搭建的时候,均是参考秦三厂的建设思路建设。
3.1.1方家山PI系统架构改造及数据接口优化
1)接口现状分析
方家山核电工程是秦山一期核电工程的扩建项目,工程规划容量为两台百万千瓦级压水堆核电机组,采用二代改进型压水堆技术,国产化率达到80%以上。当前现状为首先将unit2机组数据汇集到位于unit1机组PI服务器中,然后转发至外网PI数据库,该方案在生产中问题逐渐暴露,当unit1机组大修时,现场设备断电,内网PI服务停机,影响了unit2机组的数据外送。
另外,为保证现场工业设备处于运行最优状态,方家山生产单元采用定期预维策略,当一号机组执行预维工作期间,会影响二号机组的数据完整性。改造前unit1和unit2机组统一汇集到一个内网PI数据库中,然后由CNI接口穿透隔离装置转发至外网的PI数据库集群中。如下图1所示:
 图1:为PI实时数据库改造前/后的网络拓扑图
图1:为PI实时数据库改造前/后的网络拓扑图
为解决此问题,信息部门设计了如上图1中的解决方案,改造后unit1和unit2机组分别写入到各自内网PI数据库中,然后由CNI接口穿透隔离装置转发至外网的PI数据库,很好的解决了数据纠缠和安全方面的问题,极大的提升了实时数据的稳定性与准确性。
2)系统架构设计与部署
DCS历史数据迁移补写PI系统问题。
由于PI数据库接口长期处于不稳定状态,导致大量DCS level2历史数据无法传输至LEVEL3,滞留在DCS二层服务器上,时间过长将出现硬盘空间不足问题,另外,缺失部分的数据也需用于方家山机组运行10年评审的相关工作,因此需实施数据迁移将此部分数据移入PI数据库。
DCS系统与PI数据库接口网络结构优化。
PI数据库与PI数据接口程序安装在同一台机器上,且1、2号机组公用此接口程序,然后转发至外网PI数据库,该方案在生产运行期间问题逐渐暴露,当1号机组大修时,现场设备断电,内网PI服务停机,将影响2号机组的数据外送,此为单一故障,需要消除。
DCS系统与PI系统数据库接口程序优化。
日志文件(TXT文本)未写入到PI数据库,无法对日志信息加以利用,不利于故障/事故追忆,也需对此进行优化。
3.1.2秦二厂PI系统的架构设计及推广部署
1)接口现状分析
秦山二期核电站共包含四台机组,装机容量为别为650WM。其中1、2机组DCS由北京广利核公司实施,3、4号机组DCS由福克斯波罗实施。目前二期运行的数据主要存储0KIT系统,0KIT系统受限于其自身底层接口的制约,每台机组DCS接入数据不超过4000点。另外,前期将OKIT数据传输至管理大区采用了SQL数据库存储数据,导致传输到管理网的数据极少。这样不利于工程师对现场设备工况的监控与数据分析。
2)系统架构设计与部署
系统架构设计
根据现场DCS的架构与接口支持类型,1、2号机组采用OPC通信协议,3、4号机组采用UDP定制通信协议。为保障数据数据传输时的稳定性,同时完成1,2号机组保存在DCS和KIT系统中全量数据的传输。如下图2所示:在DCS技术改造时在工程师站后面增加了数台接口机用于传输数据。此举既保证了数据的全量传输,也保证了传输过程中不会影响工程师站的工作效率。
 图2:秦二厂PI系统架构图
图2:秦二厂PI系统架构图
1,2号机组建设方案
根据机组DCS系统的接口支持情况,双方确认1、2号机组数据通信协议采用OPC通信协议。虽然在1KIT中存储了部分DCS数据,但数据无法满足核电信息化建设的需求。且因为1KIT与1DCS位于不同的域中,在建设OPCServer时,无法将1DCS与1KIT组建到同一个Server,因此需要分别建设OPC Server服务器以及KIT 系统接口机。2号机组与1号机组情况相同,采用OPC通信协议,分别建设DCS和KIT的接口服务器。
3,4号机组建设方案
根据机组DCS系统的接口支持情况,目前有两种方案可以实现3、4号机组到PI系统的数据传输,分别为OPC通信协议和UDP定制通信协议
采用UDP通信协议主要由双方事先约定UDP包的数据格式,然后DCS端AIM API Server将DCS数据打包成UDP数据包,发送到到PI接收端。PI接收端(接口机)将收到的UDP数据包按照实现约定的格式进行解析,然后写入PI数据库。
3.1.3 秦一厂PI系统的架构设计及推广部署
1)接口现状分析
秦一厂作为中国第一台30Wkw核电机组,由于历史悠久,在前期设计时未具备实时数据传输的条件,也未保留数据接口。为贯彻数字化核电的相关要求,公司在进行秦一厂延寿项目时,加入了DCS数字化改造项目。此举不止完成了电厂延寿项目的相关工作,更在此基础上提升了机组DCS控制系统的安全性和稳定性。除此之外,改造完成后的DCS达到了数字化核电的相关要求,也具备了实时数据传输相关条件及接口接入功能。这为数据传输入PI提供了基本条件。
在DCS数字化改造之前,秦一厂仅将100个数据点,以分钟级的频率通过TXT文档的形式传输至管理大区,此方式局限性及稳定性都无法满足数据追溯及设备分析的要求。通过秦一厂PI系统的建设,现在共计4000+的秒级实时数据传输至管理大区供用户查看、分析,实现了用户远程设备监控和数据实时共享的目标。
秦一厂采用国产DCS,并提供主流的标准OPC数据接口协议,信息部门通过对接口分析,针对秦一厂定制化开发了OPC数据接口,并且满足了数据传输进入方家山生产单元PI系统的相关要求。
2)系统架构设计与部署
在架构设计方面,在满足机组网络安全的前提下,将秦一厂数据接入方家山的PI系统中。在2014年方家山PI系统的规划阶段,信息部门考虑到后期秦一厂数据的接入工作,将方家山生产单元的PI数据库点的数量预留的较为充裕。此举不止满足了数据的正常传输,也为公司节省了百万及的资金成本。
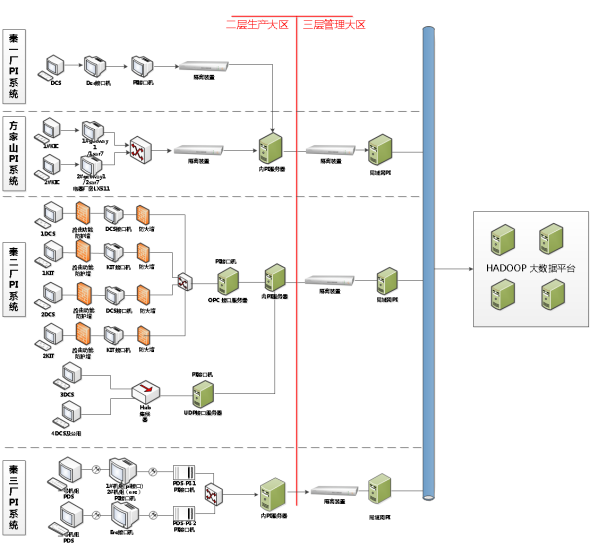
图3:秦山核电PI系统网络拓扑图
3.2 建立PI系统与Hadoop大数据平台的数据传输接口
3.2.1大数据技术在电厂生产工艺数据处理中的应用
为了应对海量数据处理的需求,以Hadoop为代表的大数据计算技术为时序数据库产品的发展提供了更好的替代方案,采用大数据技术,可以消除单机处理能力的限制,极大地拓宽时序数据库产品的处理能力。
1)Hadoop大数据平台的特点
Hadoop技术的核心是HDFS分布式网络文件系统和Map/Reduce的分布式计算框架[2],将所有的计算分为可以并行进行的部分(Map)和只能串行处理的部分(Reduce)两部分,可以获得非常高的总体处理性能。其主要技术特点如下:
高可靠性,集群内所有DataNode地位相同,所有的存储数据采用多份冗余存储(缺省保持3份),任何一台Datanode下线都可以自动由冗余的节点替代,不会影响正常运行;
高扩展性,Hadoop集群可以方便地扩展到数以千计的节点,随着Hadoop集群的扩展,Map计算会自动扩展到所有的Datanode节点;
高效性,Hadoop能够在节点之间动态地移动数据,分配计算任务时力求各个节点的负荷基本平衡,因此处理速度非常快。
2)时序数据库-Hadoop大数据平台传输接口搭建
接口程序用于实时的将PI中的数据取出,流程如下:
(1)加载接口配置文件信息,根据配置信息连接PI和Kafka;
(2)根据测点列表信息在PI服务器端注册获取数据的队列;
(3)接收PI服务推送过来的数据同步消息,解析并获取数据;
(4)转换数据格式为标准通用Event格式;
(5)发送Event格式的数据消息集合到CDH集群的Kafka消息队列;
(6)如此循环执行3到5步,直到接口被关闭。
数据采集接口采用OSI公司提供的PI-API,从PI获取数据之后经过数据格式转换之后发送到Kafka消息队列。具体API说明如下:
(1)pisn_evmexceptionsx 获取队列数据
(2)pisn_evmestablish 队列注册
(3)pisn_evmdisestablish 队列注销
3.2.2 Hadoop大数据平台数据架构
本项目采用Hadoop大数据平台的Namenode+Datanode的部署架构,综合运用消息队列技术、高速缓存技术、为生产工艺数据的采集、转换、接入和应用提供支持。目前,平台共完成约67000余个测点数据的存储[1]。下图4所示为整体架构:

图4:秦山核电Hadoop系统总体架构
处理流程如图5所示,接口程序将工艺数据从时序数据库PI中读出,并投递给Kafka消息队列,由Kafka转发给Spark Streaming组件进行处理。处理后的数据,分别存入Redis缓存数据库和Hbase数据库,完成数据从时序数据库到大数据平台的传递,下文将对其中使用到的关键大数据技术逐一进行介绍。

图5:秦山核电Hadoop系统数据接入架构
3.2.3 Hadoop关键技术及使用方法
Kafka
kafka是消息中间件的一种,通过发布和订阅消息流的机制,构建实时的流数据管道,可靠地获取应用程序的数据。Kafka以群集模式部署,通过zookeeper技术支持分布式处理,与大多数消息系统(如ActiveMQ 或 RabbitMQ)比较,kafka有更好的吞吐量、内置分区、副本和故障转移,有利于处理大规模的消息。Kafka工作原理如下图6所示:

图6:Kafka工作原理图
在秦山核电的Kafka应用设计中,为秦一厂、方家山、秦二厂、秦三厂以及未来计划接入的福清、海南、田湾、三门的PI系统分别建立相应独立的topic,为数据传递建立专门通道,防止相互干扰。
Spark Streaming
Spark Streaming是建立在Spark上的实时计算框架,可以结合流式、批处理和交互试查询应用。Spark Streaming的基本原理是将输入数据流以时间片(秒级)为单位进行拆分,把每块数据作为一个RDD,每个块都会生成一个Spark Job,使用RDD操作处理每一小块数据。在Spark Streaming中,提出了DStream的概念,代表了一个连续的数据流。可以从来自不同数据源的(如Kafka, Flume和Kinesis)输入数据流中创建[3]。

图7:数据处理流程
在秦山核电时序数据处理过程中,具体流程如下:
(1)从Kafka对应的Topic中获取消息(测点名称@测点数值@时间戳@数据可信度),并通过Spark Streaming配置启动流作业;
(2)读取HBase中测点元数据并作为广播变量传入Spark Streaming作业;
(3)以配置的固定间隔从Kafka消息中获得JavaInputDStream;
(4)对照Hbase中读入的元数据,检查Kafka消息的准确性(测点是否存在、测点值类型是否正确等),对于不准确的消息进行排除;
(5)遍历DStream中的每个RDD,解析RDD中的消息体,转换生成写入大数据平台数据库所需的实体对象RDD,调用大数据平台数据库写入API进行实时数据的同步写入;
(6)更新Kafka topic各个分区在Zookeeper中的偏移量。
Redis & Hbase
Redis数据库作为典型的NoSQL型数据库,存储格式为Key-Value,由于其具有全内存存储、支持群集模式、主从复制等优点,正在得到越来越广泛的使用[4]。
HBase主要依靠横向扩展,通过不断增加服务器,来增加计算和存储能力。HBase采用Master/Slave架构,按照RowKey分为多个Region的分区方式存储数据,数据在Region内部以RowKey的顺序排列。HBase的检索支持通过单个Rowkey访问、通过RowKey范围扫描以及全表扫描这三种方式,其中,单个Rowkey及RowKey范围扫描效率很高[5]。
在秦山生产工艺数据存储的数据库架构设计中,充分结合上述两个产品的特点,因HBase底层所使用的HDFS分布式文件系统,其在海量数据的结构化存储和查询方面具备一定优势,所以如数据的持久化,历史数据查询和时序数据库相关元数据信息等均由HBase提供服务。同时因其提供类似关系型数据库中的存储过程类的技术,HBase承担了如趋势值查询、插值查询、矩阵查询、时间加权平均等一些需经过复杂计算而提供的查询服务。Redis作为一款基于内存的Key-Value NOSQL数据库,几乎不与磁盘交互,特别擅长需频繁更新替换或查询的简单无结构关系的数据。因此快照(测点的最新值)的保存和查询由Redis负责,还有测点关键元数据信息等也都会在Redis中做缓存。
当大数据平台接收到写入数据的请求时,为了防止机器宕机导致的数据丢失,数据首先被写入到Hbase做持久化保存,而后,再写入Redis相应测点队列中。当大数据平台有快照查询请求时,数据库会直接到Redis中找到相应测点的队列,将队列的数据返回。当有历史数据或高级计算查询时,时序数据库则直接到HBase查询并返回。这样设计的目的是为了尽可能缓解Hbase数据库的查询压力,将Redis作为Hbase的Cache,响应无结构化的简单查询。
在Hbase表结构设计时,为了尽可能使得查询模式为单个Rowkey及RowKey范围扫描,根据业务场景,对Rowkey的组成进行了优化:
Rowkey的规则为散列值(3个字符)+ tag_id(8个字符)+ timestamp(13个字符,10位UTC秒数字符串+3个毫秒字符),共24个字节。其中,tag_id采用电站缩写、机组缩写数字和接入源测点的原始编码三段式组合,组合字符采用“-”,例如:Q2-3-U3RCP110MT表示秦山二厂 3机组RCP001PO电机下部径向轴承温度。这样设计的目的是,在查询时,如果查询条件设计时间、测点名称、测点所属电厂、测点所属机组,可以直接对RowKey进行索引,避免全表扫描,提高查询效率。散列值的设计为了避免产生数据热点问题,即如果使用hbase自动分区策略(Hbase会对RowKey排序存储),读写会集中到一个或者几个region上,而无法充分利用存储集群的能力。随机字符串生成方式使得region所管理的start-end keys范围比较随机,那么就可以解决读写热点问题。
3)应用效果
数据查询
 为了对大数据平台的数据处理性能进行评估,本文随机选取了测点,对日常应用中常用的原始值数据查询场景进行测试,为了防止偶然性,每个测点的查询均执行3次,以下是查询结果:
为了对大数据平台的数据处理性能进行评估,本文随机选取了测点,对日常应用中常用的原始值数据查询场景进行测试,为了防止偶然性,每个测点的查询均执行3次,以下是查询结果:
从查询结果可以看出,当查询的时间跨度达到半年、一年,数据量级达到百万、千万级时,传统的时序数据库产品PI已经无法应对如此大量的数据处理请求。而Hadoop平台可以用较高的效率处理这些数据请求,使得过去不可能实现的功能成为可能,为后期数据的应用奠定了坚实的基础。
秦山核电作为国内首个运行堆年达到百堆年级别的核电基地,积累了大量宝贵的设备运行数据,借助于大数据的列式存储、分布式处理技术,使得对于这些数据的应用变得不再遥不可及,有助于挖掘数据的潜在价值。
四、总结
通过完成对秦山核电时序数据传输系统的推广和大数据Hadoop平台的建设,完成了公司对底层工艺数据平台的统一规划,确保了电厂机组全生命周期实时数据的存储、备份以及对数据的分析、查询、大数据计算和数据再利用。满足了业务人员对生产工艺数据即查即用的需求,极大的提升电厂各系统、设备的管理水平,提高电站工艺系统和设备的可靠性和可利用率。
Hadoop大数据平台采用分布式存储技术与列式数据库+高速缓存的数据处理引擎,解决了海量生产工艺数据的使用难题。秦山核电作为国内首个运行堆年达到百堆年级别的核电基地,积累了大量宝贵的设备运行数据。Hadoop大数据平台对于时间跨度达到半年、一年甚至更久,数据量级达到百万、千万级、亿级的趋势分析请求,仍能够保持准确、高效的结果返回,为生产工艺历史数据的使用提供了保障,对数据潜在价值的挖掘与进一步利用打下了坚实的基础。
参考文献
[1] 田秀霞等,基于Hadoop架构的分布式计算和存储技术及其应用,上海电力学院学报第27卷,第1期,71-74;
[2] 许春玲等,分布式文件系统HadoopHDFS与传统文件系统LinuxFS的比较与分析,苏州大学学报(工科版),第30卷第4期,5-9
[3] 郭慈等,基于Spark核心架构的大数据平台技术研究与实践,电信工程技术与标准化,2016年第10期,40-44
[4] 曾超宇等,Redis在高速缓存系统中的应用,《微型机与应用》2013年第32卷第12期,11-13
[5] 景晗等,基于MapReduce和HBase的海量网络数据处理,科学技术与工程,第15卷第34期,183-190
作者简介:
[1]陈雨(1987-),男,汉族,工程师,大学本科。主要从事核电厂生产业务数据及三维可视化应用。联系方式:15888386018 chenyu01@cnnp.com.cn

客服QQ:30444492琼网文【2021】1550-113号
增值电信业务经营许可证:琼B2-20210322
出版物经营许可证:新出发龙华出字第(2021)009号
广播电视节目制作经营许可证:(琼)字第00779号
版权所有 ©2002-2024 期刊网(www.qikanchina.com) 琼ICP备2021005105号



