广州市交通规划研究院有限公司 广东广州 510000
摘要:区别于传统的基于单车历史数据的时间序列预测模型,本文创新性的引入了高德地图POI数据,将共享单车运营数据与POI数据通过真实地理坐标关联起来,并使用了机器学习方法,搭建并训练了多层神经网络模型来对POI数据与单车数据进行学习,挖掘二者之间的潜在关系,用于进行区域单车出发量和到达量的预测。使用了相关系数R2和均分误差MSE来对模型预测结果进行评价,模型在测试集上R2可达0.8,而在训练集上可达0.95,充分证明模型有效性。
关键字:POI;共享单车数据;神经网络算法;
共享单车是短距离出行的重要工具,有助于解决城市交通“最后一公里”出行问题。其的流动往往是不均衡的,需要进行人为管理与调度才能确保各个区域的用户有车可骑且不会因为单车量过多而挤占城市公共空间。不管是共享单车的调度问题还是停放点布置,都离不开需求量预测。目前国内使用了较粗糙的同心圆模型[1],随机森林和迭代决策树模型[2]。国内已经有多项研究发现建成环境对于共享单车使用量有影响,包括了人口密度、岗位密度、用地混合程度以及距公交站点的距离[3],基于GWR(地理加权回归)发现有桩共享单车站点附近250m的POI与共享单车使用量存在相关性[4]。
本次研究选用了高德地图公开的POI数据,并将其与膜拜单车的运营数据关联起来。通过神经网络机器学习的方法分析区域内POI数据与区域内共享单车出发量和到达量之间的关系,并分别建立预测模型,以期能够预测区域共享单车的出发量和到达量,为各类区域的共享单车投放量提供参考[5]。
2. 数据使用
2.1数据来源
本文使用的数据来源于2018年8月26日~9月8日的摩拜公司共享单车数据和自主获取的高德的开放地图POI数据,研究区域范围为上海的外环以内。共享单车数据属性如表1所示。
表1 共享单车数据属性
BIKE_ID | DATA_TIME | LOCK_STATUS | LONGITUDE | LATITUDE |
单车代码 | 时间 | 锁状态 (0:开锁,1:关锁) | 经度 | 纬度 |
POI数据是城市地区的电子地图兴趣点,主要包括城市内具有标志性作用的实体建筑物,并描述空间和属性信息。每个兴趣点都有对应描述信息,包括经纬度、区位、地址、名称、类别(大类、中类、小类)8个字段。类别中共包含19个大类,126个中类,1202个小类。大类包括餐饮服务、地名地址信息、风景名胜、公共设施等。这些地理实体的数目以及各类实体之间的比例较大程度的反映了城市的用地情况与规模,不同的用地特征对应着共享单车不同的出行需求与特征。以POI数据信息做需求分析,以共享单车数据做供给分析,建立共享单车出行方式的供需关系,可以用于指导共享单车投放。
2.2数据描述性统计
2.2.1时间特征
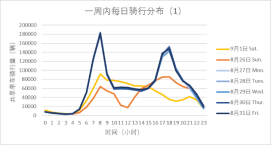

图1 一周内每日骑行交通分布
表2 天气情况
日期 | 8月26日 | 8月27日 | 8月28日 | 8月29日 | 8月30日 | 8月31日 | 9月1日 |
天气 | 小雨 | 晴 | 晴 | 晴 | 晴 | 晴 | 中雨 |
日期 | 9月2日 | 9月3日 | 9月4日 | 9月5日 | 9月6日 | 9月7日 | 9月8日 |
天气 | 晴 | 晴 | 小雨 | 晴 | 晴 | 中雨 | 晴 |
从图1中可以明显的看出周末(橙色系)骑行交通分布与工作日(蓝、绿色系)有很大差异,工作日骑行总量大于周末,说明在很大程度上共享单车被通勤用户使用。工作日呈现出明显的早晚高峰,早高峰持续时间短于晚高峰的持续时间。此外还出现了中午的次高峰情况,可能是部分用户就近用餐导致。周末的骑行交通以购物、娱乐等非通勤为主,无早晚高峰的情况。9月7日天气情况为雨天,骑行曲线特征与其他工作日不完全相同,可以一定程度上认为,雨天对共享单车的使用有很大的影响。
2.2.2空间特征
采用核密度分析方式,对工作日、周末单日共享单车数据绘制热力图。可以看出,点要素的聚集程度从市中心向外环呈现递减的趋势,内环以内的区域高于内环以外,反映了市中心城市建筑密集,共享的单车用户使用频率更高。除此之外轨道站点周围有明显的点要素集聚的情况,共享单车确实是一种有效的接驳轨道交通的出行方式。

图2 工作日单日共享单车骑行热力图

图3 周末单日共享单车骑行热力图
3. 数据分析
3.1数据预处理
本文主要分析上海市外环以内的区域,在分析之前要进行数据预处理,包括4个步骤:
一是确定数据的研究范围。根据数据的经纬度字段,使用ArcGIS提取了坐标落在上海外环以内的部分。与之对应,POI数据也同样提取同样范围。
二是数据清洗。清除单车和POI数据中的冗余数据、无关数据,具体包括筛选出具有成对OD的单车数据,删除了雨天当天的单车数据,并对工作日与周末的单车数据进行区别对待。
三是数据栅格化。使用ArcGIS将投影坐标系中的上海外环以内区域,按500m*500m的尺寸对区域进行划分。每个区域被视为一个栅格小区,因为数据边界并不是规则的正方形,因此删除了位于数据边界的栅格,确保每个栅格都被数据完全覆盖,最终得到2649块栅格。共享单车数据被处理为该栅格中的出发量和到达量,POI数据被处理为各类poi单位在该栅格中的数目。
四是数据加工。由于单车数据是多天数据,而本次研究是对单车单天内数据进行预测,因此在剔除了雨天数据后对多天的数据进行了平均处理,得到工作日的单车数据和非单车数据。同时,按各条记录的时间进行汇总,得到一天24小时内,各个小时段中的单车OD量。
3.2指标确定
栅格i的出发量即以栅格i为起点的出行量,栅格i的到达量即以栅格i为终点的出行量,本文将一周内工作日和非工作日栅格i的出发量和到达量的平均值直接作为被预测指标。
直接使用POI的数量作为预测的输入指标,由于部分POI类别数量过少会对预测结果产生影响,因此需要对POI数据进行预处理分析,本文将出现频次少于100次的POI类别直接删除,最后得到的POI类别包括银行、高等院校、麦当劳等,共186类。最终计算得到每小时栅格i的活跃单车量数据以及小类POI数量,得到的训练数据集如表3所示。
表3 训练数据示例
单车数据 | POI数据 | |||||||
栅格编号 | 0 | 1 | … | 23 | KTV | 麦当劳 | … | 超市 |
6 | 0 | 1.5 | 7 | 0 | 0 | 2 | ||
7 | 2.5 | 3 | 14 | 0 | 1 | 2 | ||
… | ||||||||
3226 | 0 | 0 | 0 | 1 | 1 | 3 | ||
3.3神经网络预测模型
3.3.1 前馈神经网络
前馈神经网络是一种简单的神经网络,由输入层、隐藏层、输出层组成,每层包含特定数目的神经元,层与层之间存在连接,其输入输出关系如下:
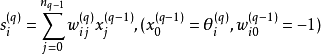
![]()
![]()
这时每一层相当于一个单层前馈神经网络,如对第q层,它形成一个![]() 维的超平面。它对于该层的输入模式进行线性分类,但是由于多层的组合,最终可以实现对输入模式的较复杂的分类。
维的超平面。它对于该层的输入模式进行线性分类,但是由于多层的组合,最终可以实现对输入模式的较复杂的分类。
3.3.2 网络结构
本次研究使用的神经网络模型共五层,包括输入层,隐藏层,输出层,使用RELU作为激活函数。
3.3.3 模型训练
除模型网络结构外,模型训练涉及到训练数据、优化算法、损失函数、训练过程等方面,各方面的详细情况介绍如下:
训练数据:训练数据为经过预处理的单车及POI数据,其中,模型是输入数据是各栅格186种POI子类的数目,输出数据是该栅格24个小时分别的活跃单车量。为进行模型测试,预留了20%的数据作为测试数据,故训练数据共4238条。
优化算法:使用Adam算法,Adam算法是机器学习领域最常用的优化算法之一,具有学习率自适应的特点,优化效果较好。在本次研究中,设定初始的学习率为0.001,正则化系数为0.001。
损失函数:使用均方误差(MSE)作为损失函数,本次研究是对车辆数的预测,模型的输出是数值变量,因此是回归问题,而MSE是解决这一类问题最常用的损失函数。
训练过程:训练过程中需要分批进行训练,并进行多次迭代,在本次研究中,使用的批量为64,迭代次数上限为200次。
4. 原型测试
4.1测试方法
本次研究使用了五分交叉验证的方法对模型进行测试。模型结果的评价指标包括回归分析常用的R2指标以及均方误差。R2反映了X对Y的解释能力,均方误差反映出预测值与准确值之间的差异程度。
4.2 测试结果
使用同样的模型,分别使用出发量和到达量数据对模型进行了训练和测试。测试结果分别如下:
(1)出发量模型结果
模型使用五分法进行测试的结果及如下:
表4 出发量模型结果
训练集 | 测试集 | |||
R² | MSE | R² | MSE | |
组1 组2 组3 组4 组5 最佳 | 0.95 0.91 0.90 0.92 0.91 0.95 | 36.00 72.73 67.84 137.84 50.49 36.00 | 0.80 0.75 0.64 0.77 0.72 0.80 | 182.68 344.80 402.56 316.85 556.23 182.68 |
(2)到达量模型结果
模型使用五分法进行测试的结果如下:
表5 到达量模型结果
训练集 | 测试集 | |||
R² | MSE | R² | MSE | |
组1 组2 组3 组4 组5 最佳 | 0.91 0.94 0.96 0.94 0.93 0.94 | 88.57 41.53 35.52 31.22 56.33 41.53 | 0.81 0.84 0.72 0.80 0.71 0.84 | 132.00 237.39 347.61 330.92 404.38 237.39 |
5. 结论
本研究通过神经网络,探索出城市栅格小区内兴趣点小类数量和单车出发量和到达量之间的关系,建立预测模型。建立该模型之后,可以为摩拜单车的投放量提供参考。摩拜单车公司可以利用该模型更加精准的进行区域投放,减少过量投放带来的共享单车占用公共空间过多的问题,为共享单车的可持续发展奠定基础。
参考文献
[1] 夏芸,玉琦彤,林子立.共享单车需求评估及调度方案设计[J].长安大学学报(社会科学版), 2018,v.20;No.73(02):38-47.
[2] 焦志伦,金红,刘秉镰,张子豪.大数据驱动下的共享单车短期需求预测——基于机器学习模型的比较分析[J].商业经济与管理,2018(08):16-25+35.
[3] Rixey R A. Station-Level Forecasting of Bikesharing Ridership: Station Network Effects in Three U.S.Systems[M].2012.
[4] Bao J, Shi X, Zhang H. 9 Smart Card and POI Data Using Geographically Weighted Regression Method[J].IEEE Access, 2018, 6:76049-76059.
[5] 张再兴,邓志东,孙增圻. 智能控制理论与技术(第2版)[M]. 清华大学出版社,2011:134-140

客服QQ:30444492琼网文【2021】1550-113号
增值电信业务经营许可证:琼B2-20210322
出版物经营许可证:新出发龙华出字第(2021)009号
广播电视节目制作经营许可证:(琼)字第00779号
版权所有 ©2002-2024 期刊网(www.qikanchina.com) 琼ICP备2021005105号



