河北外国语学院 邮编:050000
摘要:德语是德国的官方语言,也是欧盟境内使用人数最多的母语,全世界约有2亿人使用德语进行交流,庞大的德语使用人群贡献了不计其数的德语数字化文本信息。与汉语、英语等语言相比,目前国内外对德语文本挖掘的研究较少,还远未成熟,准确性不令人满意。其中,德语文本聚类研究仍处于起步阶段,目前尚未见国内外有系统的德语文本聚类方法研究,而当前较为成熟的汉语和英语文本聚类方法无法直接应用于德语文本聚类。
关键词:特征词配对;德语;文本聚类方法
引言
深度神经网络在将原始文本映射到潜在空间的过程中,不同层次的神经网络能够学习到文本不同的潜在子空间语义信息。然而传统深度文本聚类方法目前虽取得了较好的聚类效果,但其还存在聚类时依赖的语义表示单一,只利用了中间层最低维的潜在语义表示而忽略了不同层具有的其他的有效信息,即仅利用中间层一层的文本语义表示进行聚类,没有考虑到不同层次的神经网络学习到的不同文本潜在子空间语义表示的问题。
1基于FWP的德语文本相似度计算
基于特征词配对(FeatureWordsPairing,FWP)的德语文本相似度计算的核心思想为:通过计算余弦相似度,将源文本中每个特征词与目标文本中每个特征词进行配对,累加所有配对单词的匹配度,将其作为源文本和目标文本的文本相似度。其详细步骤为:Step1:假设现有两篇文本,为表区别分别称为源文本与目标文本,如图1所示,经特征词选择得到源文本特征词集合Ds=[ws1,ws2,…,wsn]和目标文本的特征词集合Dt=[wt1,wt2,…,wtn]。其中wsi表示源文本Ds中第i个特征词的词向量,wtj表示目标文本Dt中第j个特征词的词向量,i,j∈[1,n],n为特征词的个数。

Step2:构建形如公式(1)的相似度矩阵,矩阵中第i行第j列的元素等于源文本Ds中的第i个特征词wsi与目标文本Dt中第j个特征词wtj的余弦相似度,记作Simwsi,wtj()。

Step3:从相似度矩阵中的第1行的所有元素中筛选出最大值,将其作为特征词ws1与wtj的匹配度(在此假设最大值为Simws1,wt2()),记为MS1,如公式(2)所示:
![]()
并称此时ws1与对应的wtj为一个特征词配对(图1中使用实线表示,即ws1与wt2为一个特征词配对)。Step4:类似地,遍历相似度矩阵中剩余的每行元素,从第i行的所有元素中筛选出最大值,将其作为wsi与wtj的匹配度MSi(即图中MS2,…,MSn),如公式(3)所示:
![]()
并称此时wsi与对应的wtj为一个特征词配对(图1中使用实线表示,即ws2与wtn为一个特征词配对,wsn与wt1为一个特征词配对)。值得注意的是,此时可能出现不同的wsi与同一个wtj配对,这种情况是被允许的,即wtj可以与多个wsi配对。Step5:汇总Step3和Step4中配对单词的匹配度,得到匹配度集合{MS1,MS2,…,MSn},对集合中的每个值进行累加,将累加值作为Ds→Dt的累计匹配度,记作Match(Ds→Dt),如公式(4)所示:
![]()
Step6:与Step3~Step5类似,遍历相似度矩阵中的每一列元素,从第j列的所有元素Simwsi,wtj(),i∈(1,n)中筛选出其中的最大值Max(Sim(wsi,wtj)),得到wsi与wtj的匹配度MTj,如公式(5)所示:
![]()
累加所有MTj,将累加值作为Dt→Ds的累计匹配度MatchDt→Ds(),如公式(6)所示
![]()
Step7:将Ds→Dt的累计匹配度与Dt→Ds的累计匹配度的均值作为Ds与Dt的文本相似度,记作Sim(Ds,Dt),如公式(7)所示:
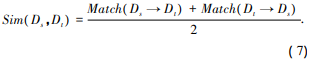
对Step7的说明:在实际过程中,在某些情况下可能会出现Ds→Dt的配对关系与Dt→Ds的配对关系不一致的问题。如图2所示,Ds→Dt的配对关系为{ws1,wt2(),(ws2,wt1)},而Dt→Ds的配对关系为{wt1,ws1(),(wt2,ws1)}。这种情况出现的原因是在Step4中允许一个特征词与多个特征词同时配对。为了减少这种情况带来的影响以及考虑到相似度的对称性,故将Ds→Dt的累计匹配度与Dt→Ds的累计匹配度的均值作为Ds与Dt的文本相似度。

2聚类模型的语义增强
改进分组模型的语义,特别是深度分组模型,仍然是一个研究热点。相关的研究结果包括用于解决单词独立性问题的关键词嵌入方法、将合并单词向量与上下文语义和dillinger过程相结合的主题模型(ETM)。在这些方法的基础上,提出了一个集中的转换过程,以改变主题分布,从而捕获主题之间的相似之处。尽职调查层次结构(HDP)使用DP在主题之间建立链接,其前提是每个主题的主题和单词分布与DP生成的基本h分布相同。同样,传统的DP已被纳入VAE模式。简而言之,一系列基于VAE的深度群模型可以提高培训的效率和一致性,同时确保模型的可解释性,但从模型的语义完整性的角度来看,它们在培训过程中直接忽略文本中缺少的语义信息,从而导致性能下降。
3算法分析
对基于FWP的德语文本相似度计算方法的分析:(1)FWP是一种无监督的方法。FWP不需要依赖于标注的数据,通过寻找文本间配对特征词的相似度来量化表示文本间的相似程度,可以在任何类型的文本数据中使用。(2)FWP模型较为简单。FWP仅需要各文本的特征词向量作为输入,即可得到文本相似度矩阵输出,在此过程中的超参数仅有特征词个数,简化了使用过程。(3)FWP可以避免特征词的信息丢失。与传统的相似度方法相比,FWP在相似度计算过程中,保留了每个特征词的信息,避免文本向量受到均值化的影响,使得结果更加科学合理。(4)FWP具有更高的区分度。FWP将n对特征词的匹配度累加结果作为文本相似度,相似度范围为-n,n,远远大于余弦相似度方法的相似度范围,这样使得不同文本之间的相似度差异更为明显,更具有区分性。(5)FWP具有可解释性和可预测性。FWP的值越大,代表两篇文本的特征词越相似,则两篇文本内容的相似程度越高,即FWP具有可解释性。同理,当两篇文本越相似,则可预见地FWP的值也会越高,即FWP具有可预测性。
4基于增强语义表示的聚类算法
传统的深度聚类模型只考虑了数据自身内部内容语义来学习语义数据表示。除了内部语义之外,还有一些其他有用的信息可以用于增强语义表示的学习。近年来,图结构信息常用来学习数据的结构语义表示,典型的传统方法是谱聚类,它将样本作为加权图中的节点,使用数据的图结构聚类。随着深度神经网络的发展,近年来图卷积神经网络(GCN)在深度语义表示学习方面表现优异,它不但包含图结构语义信息还具有样本数据自身的特征。基于GCN成功的启发,有许多研究已经成功的使用GCN模型对图聚类的数据结构表示进行建模,利用图结构语义表示实现深度语义增强。其中,图自编码器(GAE)模型和图变分自编码器(VGAE)模型使用两层图卷积学习数据语义表示,并分别使用自动编码器和变分自动编码器重建每个节点的邻接矩阵。为进一步增强语义表示的学习,提出的图深度聚类网络(SDCN)模型将结构信息整合到深度聚类中,并设计了一个双重监督机制用以同时监督模型的参数更新。
结束语
德语是欧盟境内使用最广的母语。由于德语词法和语法规则的复杂性以及优质平行语料的缺失,国内外对德语文本聚类的研究较少。为了支持基于德语文本的管理决策,本文借鉴汉语和英语文本聚类方法流程,针对性地研究了德语文本聚类的方法,提出一种基于特征词配对(FWP)的德语文本相似度计算方法。
参考文献
[1]李克龙. 基于自编码器的短文本聚类算法优化研究[D].西北师范大学,2021
[2]张懂懂. 基于类组织P系统的模糊聚类的研究与应用[D].山东师范大学,2021
[3]吴锦池,余维杰.融合知识库语义的文本聚类研究[J].情报杂志,2021
[4]李璐萍,赵小兵.基于文本聚类的主题发现方法研究综述[J].情报探索,2020
[5]万昊雯. 基于深度学习的短文本聚类集成方法研究[D].大连海事大学,2020

客服QQ:30444492琼网文【2021】1550-113号
增值电信业务经营许可证:琼B2-20210322
出版物经营许可证:新出发龙华出字第(2021)009号
广播电视节目制作经营许可证:(琼)字第00779号
版权所有 ©2002-2024 期刊网(www.qikanchina.com) 琼ICP备2021005105号



