池州职业技术学院,机电与汽车系 安徽池州 247000
摘要:针对PM2.5具有非线性、不确定性、难以预测的特点,提出了一种GM-AFSA-ELMAN神经网络的混合特征选择算法,首先是通过灰色关联的分析方法选出与PM2.5相关性较强的特征变量,过滤掉一些相关性小的特征变量。然后利用人工鱼群算法(AFSA)强大的寻优能力对ELMAN神经网络进行初始化、权值优化。接着利用ELMAN神经网络建立相关变量与 PM 2.5 浓度之间的软测量模型,并利用所监测到的数据对模型进行训练,最后将该模型应用于实际环境中,结果表明该方法具有较高的精度和收敛速度
关键词:灰色关联,人工鱼群算法,PM2.5
0.引言
PM2.5指的是在环境空气中空气动力学当量直径小于或等于2.5微米的长时间悬浮于空气中的细颗粒物,其在空气中浓度越高,污染越严重。它的来源非常复杂,主要来源于自然因素和人为因素,自然来源包括火山灰、森林火灾、细菌等。人为因素来源于燃煤、机动车尾气、工业粉尘等直接排放的细颗粒物,也有空气中可吸入颗粒物(PM10)、细颗粒物(PM2.5)、CO、NO2、O3、SO2 、挥发性有机化合物。据研究 PM2.5 可以渗透到人的肺部和支气管,因此长期暴露于 PM2.5 环境中会增加呼吸系统和心血管疾病的发病率和死亡率,通过对太阳辐射的吸收和散射,PM2.5 也会对全球气候变化产生影响,同时会影响能见度,进而影响我们的日常生活。因此,对 PM2.5 进行有效的预测,及时采取防控措施有重要意义。但是 PM2.5 的浓度既和污染源有关,又受气象条件的影响,使得预测难度较大。
王勖之[1]等提出了基于时间序列的ARMA模型对PM2.5浓度进行拟合分析预测,Zhu[2]等利用贝叶斯分析了PM2.5的时域变化特征,这两种方法忽略了外部气象条件对PM2.5浓度变化的影响。Liu [3]等利用自组织长短期记忆(long short-term memory, LSTM)网络, 探索PM 2.5预报的更多可能性.Huang 等构造一维卷积和 LSTM 的叠加模型, 利用 PM 2.5 浓度、风速和累计降水量来预报PM 2.5 ,获得比单一 LSTM 模型更好的效果.;Qiao[4]等利用模糊神经网络建立 PM2.5 预测模型,并采用二阶梯度下降算法训练网络,预测效果比 ESN 和化学传输模型都要好。
PM2.5的预测模型近年来不断更新,对PM2.5的预测精确问题还有很大的空间,尤其是近年来机器学习发展迅速,本文提出了一种基于灰色理论(GM)和改进ELMAN神经网络的PM2.5预测方法。首先,通过灰色关联理论确定了 16个影响PM2.5关联度的因子,筛选出最佳的影响因子作为AFSA—ELMAN的输入,然后利用人工鱼群算法(AFSA)优化ELMAN神经网络的权值和阈值,构建了AFSA—ELMAN神经网络模型。最后通过某地区3000个的实际样本数据,对比分析了AFSA-BP、AFSA—RBF共2种算法的收敛性和准确性,验证了所提方法的有效性、合理性。该模型结合了灰色理论、ELMAN神经网络以及人工鱼群算法优点,实现了对PM2.5准确预测。
1.基本理论分析
1.1灰色模型预测
灰色理论认为系统的一切过程可看做是在一定时空区域内的灰色过程,同时可通过生成变换可将系统数据无规则的序列变成有规则的序列。PM2.5的灰色预测就是应用灰色系统理论,通过对原始数据的处理和对灰色模型的建立,了解PM2.5呈现出的一定规律,对PM2.5状态进行预测[5],就是将“无规则的变量”变成“灰色变量”,灰色建模中最具代表性模型就是GM模型,下面给出GM(1,1)模型的建模过程:
(1)设原始数据列为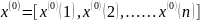 (1),n为数据的个数,对其进行一次预处理,做一次累加计算,则得到新的数列:
(1),n为数据的个数,对其进行一次预处理,做一次累加计算,则得到新的数列: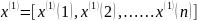 (2)
(2)
其中: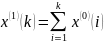 ;k=1,2,3
;k=1,2,3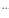 (3)
(3)
(2)求均值数列: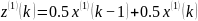 ,其中k=2,3 n。则生成
,其中k=2,3 n。则生成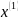 的均值数列为
的均值数列为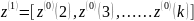
(3)根据灰色理论对 建立关于t的白化方程形式的一阶微分方程GM(1,1)则有
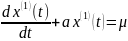 (4),其中a、
(4),其中a、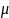 分别为发展系数和灰色作用量
分别为发展系数和灰色作用量
(4)根据最小二乘法求得参数a、 ,则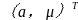 =
=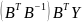 ,其中
,其中
B= =
=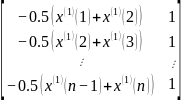 ,Y=
,Y=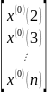
将(a, )代入 中,并求得
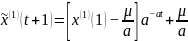 (6)
(6)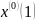 为原始数列首项;
为原始数列首项;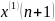 为预测数列首项,
为预测数列首项,
从而得到GM(1,1)初步预测值为:
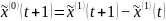
1.2灰色关联分析法
关联度的基本思想是根据几何曲线间的相似程度来判断关联程度,即几何形状越相近,则发展态势越接近,关联度就越大。根据其对PM2.5影响的关联度的大小进行分析,建立起PM2.5的预测神经网络模型,对于PM2.5的大小和相关因素量,通过关联度的计算,可以确定关联度大的因素集[7]
,在关联度分析中,不同的公式计算关联度的数值可能不同,但是关联度的大小排列次序㕁不会发生改变。为了使得扰动因素的数列之间具有可比性,就必须对数据进行归一化处理。
灰色关联分析的基本步骤:
(1)将PM2.5的浓度作为参考数列,设为
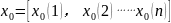
(2)将影响PM2.5大小的因素作为比较数列,设为
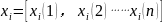
根据斜率关联度的计算公式:
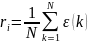
其中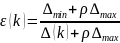 ,其中
,其中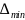 和
和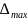 分别表示参考数列和比较数列的最小值和最大值,
分别表示参考数列和比较数列的最小值和最大值,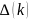 为K时刻两数列的绝对差,
为K时刻两数列的绝对差,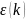 为灰色关联度系数,
为灰色关联度系数,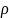 为分辨系数,通常取值为0.5,N为数据序列的长度,
为分辨系数,通常取值为0.5,N为数据序列的长度,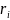 为任意时刻的平均值, 越接近于1,关联度越大则表示该指标对参考序列的影响程度越大。
为任意时刻的平均值, 越接近于1,关联度越大则表示该指标对参考序列的影响程度越大。
1.3数据来源
PM2.5来源非常广泛,成因复杂,包括煤燃烧、汽油燃烧、柴油燃烧、机动车尾气、天然气、生物质的燃烧,道路和建筑施工中的扬尘,工业粉尘等[8]。因此根据其组成来源和影响因素,包含了20个指标因子的影响体系:(1)气象原因对PM2.5影响:包括风速、气压、气温、日照时数、温度、降雨量、湿度等7个因子的指标。(2)工业生产排放的污染物对PM2.5的影响,包含NO2、SO2、PM10、CO、NH3等5个因子的指标(3)城市化与社会产业结构的发展:包含了公园绿地面积、园林绿地面积、生产绿地面积、防护绿地面积、绿地覆盖率、城乡景观、风景名胜、植物园等这些绿化都能对降低PM2.5污染的能力。同样人口密度、城市建筑面积和年GDP值等。接下来对上面的因子进行关联分析可以看出,在分析因子中其中CO、PM10、SO2、NO2、降水量、相对湿度是影响PM 2.5变化最主要的 6个关联因子,其次是最高 0 cm 地温、蒸发量、平均风速3个因子,均超过了0.7。本文选择以上 9 个因子作为PM2.5预测模型的输入特征。
2、AFSA—ELMAN神经网络的残差修正
2.1ELMAN神经网络
ELMAN神经网络是一种动态递归神经网络,它是在BP网络的结构基础上,在隐含层处增加了一个承接层。它可以记忆隐含层单元前一个时刻的状态[9],从而使系统具有适应时变特性的能力,增强了网络的全局稳定性,比BP神经网络具有更强的计算能力。如下图(2)
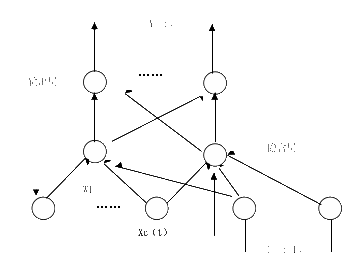
图2Elman 神经网络结构图
如上图所示,ELMAN神经网络包含了输入层、隐含层、输出层、承接层组成,假设它们的神经元个数分别为M、N、L,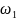 、
、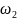 、
、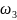 分别为输入层到隐含层、隐含层到输出层及承接层到隐含层的连接权矩阵,其数学表达式如下所示
分别为输入层到隐含层、隐含层到输出层及承接层到隐含层的连接权矩阵,其数学表达式如下所示
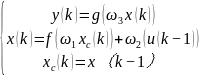
上式中y为m维输出节点向量,x为n维中间层节点单元向量,u为r维输入向量,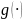 为线性函数,
为线性函数,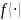 为神经网络的阈值函数,一般采用sigmoid 函数,即
为神经网络的阈值函数,一般采用sigmoid 函数,即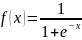
2.2AFSA—ELMAN残差校正模型
人工鱼群算法(AFSA)是一种经典式智能优化算法,通用性强,能在多个非线性的系统中解决问题且全局收敛性好,容易求得最优解。
PM2.5预测具有随机性、偶然性和非线性。本文将人工鱼群算法与ELMAN神经网络结合起来,形成AFSA—ELMAN模型,即利用AFSA对ELMAN神经网络进行权值和阈值修正,修正后的网络在训练过程中对数据充分学习,并且排除其他因素的影响,提高预测的准确度,其原理如下:
(1)在灰色建模中,根据预测值得到残差序列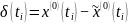
(2)对于不同数据组之间可能存在着影响,残差序列必须给于归一化处理:
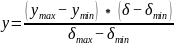 +
+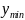
其中: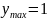 ;
;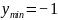
2.2.1人工鱼群算法
人工鱼群算法(AFSA)是李晓磊博士等在2002年提出的一种模拟鱼群觅食的智能优化算法。即在一片宽广的海域中,鱼群能够自己或者跟随其他鱼群找到营养物质多的地方,因此,鱼群数目多的地方就是该海域中富含营养物质最多的地方,根据这一特点来模拟鱼群的觅食、聚群及追尾行为,从而实现寻优过程,这就是鱼群算法的基本思想[10]。
假设人工鱼群的初始阶段有N条鱼,其中每条鱼的状态为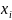 ,其中任意两条人工鱼间的距离为
,其中任意两条人工鱼间的距离为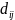 =
=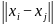 ,visual表示人工鱼的感知距离,移动步长为step,
,visual表示人工鱼的感知距离,移动步长为step,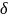 为拥挤度因子,rand()为(0,1)之间的随机数。具体步骤如下所示:
为拥挤度因子,rand()为(0,1)之间的随机数。具体步骤如下所示:
(1)觅食行为,它是指人工鱼群向着食物多的方向移动的一种行为,设人工鱼的当前状态为 ,在其视野感知器范围内寻找另一个值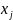 ,分别计算他们的目标函数值进行比较,若
,分别计算他们的目标函数值进行比较,若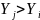 ,则 向着 的方向移动一步,否则 继续在其视野范围内群众新的状态 ,判断是否满足条件,反复尝试N次后,若仍不满足,则随机移动一步到新一个状态。则有:
,则 向着 的方向移动一步,否则 继续在其视野范围内群众新的状态 ,判断是否满足条件,反复尝试N次后,若仍不满足,则随机移动一步到新一个状态。则有:
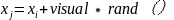
=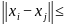 visual
visual
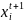 =
=
=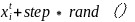
![]()
![]()
![]()
![]()
![]()
(2)聚群行为,人工鱼在游动的过程中通常为了自身的安全会自然的聚集成群。假设人工鱼的当前状态为 ,搜索在其视野范围内(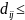 visual)的伙伴数目为
visual)的伙伴数目为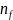 及所在中心的位置
及所在中心的位置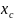 ,若经计算
,若经计算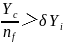 ,则表明该人感知范围内中心食物多,且不拥挤,则 朝着伙伴的中心位置移动一步,否则执行觅食行为,即:
,则表明该人感知范围内中心食物多,且不拥挤,则 朝着伙伴的中心位置移动一步,否则执行觅食行为,即:
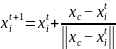 *step*
*step*
(3)追尾行为,是指人工鱼向着其视野范围内的最佳的方向移动的一种行为,假设人工鱼当前状态为 ,其适应度的最高的个体为 ,若经计算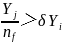 ,说明伙伴 所在的位置食物多并且不在拥挤,则 朝着 位置移动一步,否则执行觅食行为。即
,说明伙伴 所在的位置食物多并且不在拥挤,则 朝着 位置移动一步,否则执行觅食行为。即
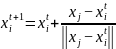 *step*
*step*
(4)随机行为,人工鱼在其视野范围内随机选择一个状态,然后向该方向移动,它本质上就是觅食行为的一个缺省行为。
在AFSA算法中,觅食行为是算法的收敛性的基础,聚群行为增加了算法的收敛性,追尾行为增加了算法的全局性。在迭代周期内准确记录每一条鱼的适应度的函数值,并且与记录值进行比较,若当前的人工鱼状态优于记录状态,则替换掉记录中的人工鱼,否则记录不变。每次人工鱼的状态与最优值进行比较,迭代过程中若找到一个最优值,则对记录进行更新,迭代结束后,记录下来人工鱼的状态即为人工鱼状态,就是所求全局的最优解
3GM-AFSA-ELMAN预测模型和评价标准
3.1预测模型
根据以上理论分析所得出的结论,GM-AFSA—ELMAN预测模型原理如下:利用距灰色模型对 PM2.5进行预测,把得到的初步预测值与真实值进行比较得到残差序列. 最后将残差序列输入到 GA-Elman 残差校正模型中,得到本文的最终预测值.具体步骤如下:
(1)对输入数据建立灰色模型GM(1,1)
(2)对输入数据进行一次累加处理,得到一阶累加序列
(3)将 序列输入到GM(1,1)模型,根据前面的公式辨识参数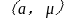
(4)由 得出的响应时间函数可以求出预测值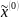 和残差序列
和残差序列
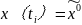 (
(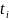 )+
)+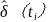 ,
,
3.2实验结果
本次实验以池州市某小区空气质量监测站为研究对象,采集该站点的小时数据。采样
时间为2019年11月1日至2021年11月7日,包括了四个季节的监测数据,样本丰富具有代表性。采样变量包括环境空气质量标准中规定的6项常规监测项目:CO、NO 2 、SO2 、O3 、PM2.5、PM10和气象变量:相对湿度、温度、气压、风向、风速、天气。经过整理获得有效数据100组,随机选择70组作为训练样本,30组作为测试样本。
3.4真实值与预测值之间的比较
首先将整理好的100组数据,其中的70组建模训练神经网络,网络训练次数为1300次,期望方差为0.08,通过仿真研究表明,得出真实值与预测值之间在过去时间当中的存在误差。如下如所示:
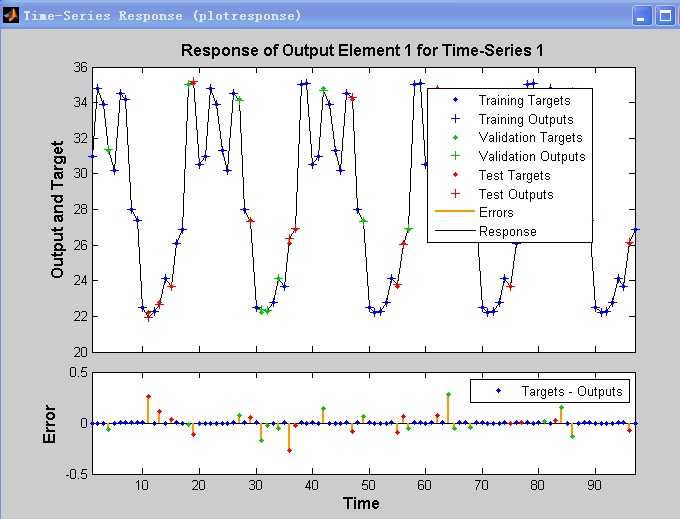
3.6模型验证
4结束语
通过以上分析及仿真结果显示,提出GM与 AFSA—Elman 算法模型在PM2.5预测中具有准确稳定的预测结果,对数据进行了充分的学习,不仅解决了PM2.5 预测的功能,同时通过该算法的结合增加了预测模型的效率。对于中长期的预测效果有待后来者进行深入的研究,该网络模型有很好的收敛性和稳定性,提高了预测精度。
5参考文献
[1]王勖之,曾沛,刘永辉.上海市PM2.5浓度的分析与预测[J].数学的实践与认识,2017,47(15):210-217.
[2]李超群.基于贝叶斯网络对全国PM_(2.5)浓度影响因素分析[J].科技创新与应用,2020(22):1-5+9.
[3]张冬雯,赵琪,许云峰,刘滨.基于长短期记忆神经网络模型的空气质量预测[J].河北科技大学学报,2020,41(01):67-75.
[4]周杉杉,李文静,乔俊飞.基于自组织递归模糊神经网络的PM2.5浓度预测[J].智能系统学报,2018,13(04):509-516.
[5]王超学,贾晓莉,孙嘉诚.DSCE-GEP算法在PM2.5浓度预测中的应用[J].计算机测量与控制,2021,29(10):71-76.
[6]韦惠红,李剑,张文言,雷建军,陈璇.基于深度学习和支持向量机集成学习的PM_(2.5)浓度24小时预测[J/OL].华中师范大学学报(自然科学版)
[7]王倩影,杨可鑫.基于LSTM-SVR混合模型的PM2.5浓度预测[J].信息技术与信息化,2021(09):33-36.
[8]王馨陆,黄冉,张雯娴,吕宝磊,杜云松,张巍,李波兰,胡泳涛.基于机器学习方法的臭氧和PM_(2.5)污染潜势预报模型——以成都市为例[J].北京大学学报(自然科学版),2021,57(05):938-950.
[9]胡占占,陈传法,胡保健.基于时空XGBoost的中国区域PM_(2.5)浓度遥感反演[J].环境科学学报,2021,41(10):4228-4237.
[10]郑俊褒,华思洁.基于GA-BPNN的PM2.5浓度预测模型[J].软件导刊,2021,20(09):28-32.
池州职业技术学院院级自然重点项目(ZR2019Z02)
第一作者:鲁明,男, 硕士,讲师。

客服QQ:30444492琼网文【2021】1550-113号
增值电信业务经营许可证:琼B2-20210322
出版物经营许可证:新出发龙华出字第(2021)009号
广播电视节目制作经营许可证:(琼)字第00779号
版权所有 ©2002-2024 期刊网(www.qikanchina.com) 琼ICP备2021005105号



